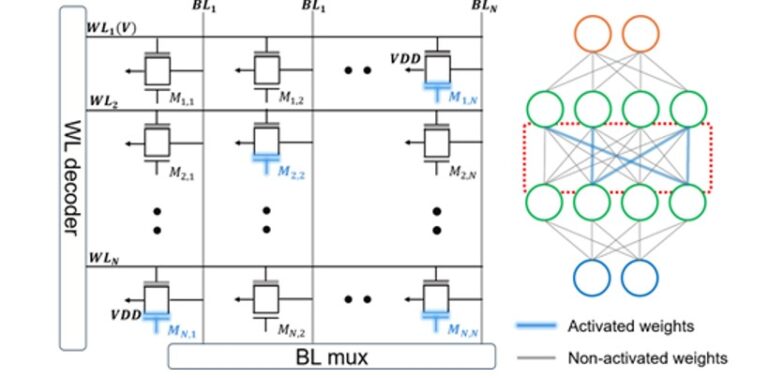
Continual learning at the edge requires energy-efficient hardware capable of dynamic adaptation from limited (few-shot) data, posing fundamental challenges to conventional von Neumann architectures due to data movement overhead and limited parallelism. In this work, we address these challenges by proposing an in-memory computing architecture based on customized dual-gate, back-end-of-line (BEOL) ferroelectric field-effect transistors (FeFETs). Integrated with state-of-the-art subnet-based learning frameworks, the proposed architecture enables energy-efficient multiply–accumulate (MAC) operations while concurrently performing subnet masking, thereby supporting rapid and resource-efficient continual learning.
A single 400 × 100 FeFET crossbar array simultaneously executes MAC and masking operations, achieving at least a 2.42× improvement in energy efficiency. Using this architecture, we obtain an average accuracy of 90.6% across 10 incremental tasks on the Permuted-MNIST (PMNIST) benchmark, comparable to a GPU-based baseline of 91.9%. With increasing model size, the proposed system consistently demonstrates at least 1.39× higher area efficiency and 2.13× faster computation speed relative to state-of-the-art implementations. These results highlight the potential of unconventional in-memory computing architectures to overcome energy, latency, and scalability limitations, paving the way for hardware-realizable continual learning in edge intelligence applications.